Bases para el periodismo de datos
Table of Contents
- Primera sesión
- Segunda sesión
- Tercera sesión
- Cuarto día
- Dudas
- Conocer distintos tipos de formatos de (intercambio de) datos
- Tipos de datos
- Conversión de datos: XML, CSV, XLSX
- ¿Necesita Open Refine conexión a Internet?
- Selección por fechas en refine y agrupación en Refine
- Grep es súper útil y lo demás sobra
- ¿Y no vamos a ver algún programita que haga gráficos?
- Gestión paquetes windows
- Github
- Hagamos nuestra propia web
- Dudas
- Quinto día
- Sexto día
- Séptimo día
- Extra
- Algunos enlaces desordenados
Primera sesión
whoami
Soy Adolfo Antón Bravo, doctor en Ciencias de la Información por la Universidad Complutense de Madrid. He trabajado durante casi diez años como socio de una cooperativa de servicios informáticos con software libre. Anteriormente trabajé de diseño web, diseño gráfico y periodista en diversos medios. Me podéis encontrar por:
- twitter: tw:adolflow
- github: gh:flowsta
- gmail: adolflow
- web: infotics.es
Presentación
El programa del curso es muy ambicioso. Cada una de las partes podría llevarnos todo el curso. No hay obligación de dar todo, pero sí que es importante que sentemos lo más sólidamente posible unas buenas bases sobre las que poder aprender de todas esas u otras tecnologías de ahora en adelante y seamos capaces de acometer todo tipo de proyectos de periodismo de datos, ya sea porque podemos hacerlo, porque podemos aprenderlo o porque podemos pedir ayuda especializada.
Al ser un curso presencial y colectivo, es importante que vayamos a la par, que aprendamos todxs. En este sentido, es muy importante decir en todo momento las dudas que tenemos, los fallos que se producen cuando intentamos hacer algo, no tener miedo a exponer la dificultad, los errores o lo que nos sugiere lo que estamos haciendo. De esta manera, no solo aprenderéis más quien realiza la pregunta sino que aprenderemos todxs, yo incluido.
Introducción al Periodismo de Datos
Dado que todxs -menos uno- sois periodistas, nos vamos a saltar la introducción al periodismo de datos ya que creo que es mejor que vayamos al turrón. directamente.
La introducción que normalmente realizo –en construcción- la podéis encontrar aquí.
Recolección de datos, ejemplo
Empezamos con una recolección de datos de todxs vosotrxs y de vuestras aptitudes para saber/ver varias cosas:
- Quiénes sois
- Qué estudios tenéis
- Dónde habéis estudiado
- De dónde venís
En esta recopilación se plantean algunas cuestiones habituales que ocurren cada vez que pensamos en un modelo de datos.
Además, hay algunos datos controvertidos por su caracter personal como:
- Edad
- Género
El proceso de recolección es una de las fases más importantes del proceso del periodismo de datos.
En relación a vuestras aptitudes, sirve para:
- Saber cómo os consideráis en relación a algunos saberes importantes para el periodismo de datos.
- Orientar las horas del curso.
Al final del curso, haremos otra recogida de datos y veremos cómo os ha ido.
Terminal
En este curso vamos a empezar por la terminal. Cuando me refiero a la terminal en realidad me refiero a una emulación de la terminal que era la interfaz de texto que tenían los ordenadores antes de las interfaces gráficas.
También se le conoce por consola, en cuanto que es una consola –aunque mucha gente lo puede confundir con una consola de videojuegos– o por línea de comandos, ya que se introducen comandos.
CLI, GUI y NUI
En la terminal se introducen comandos que ejecutan programas CLI, acrónimo que obedece a Command Line Interface o interfaz de línea de comandos.
En los entornos gráficos o interfaces gráficas hay programas GUI, acrónimom que responde a Graphic User Interface o intefaz gráfica de usuarix.
Pero también hemos trabajado -de hecho lo hacemos todos los días- con interfaces NUI (Natural User Interface o interfaz natural de usuarix) como pueden ser las pantallas capacitivas multitáctiles, Kinect –con el movimiento– o Siri o Alexia –con el reconocimiento de lenguaje natural–.
Algo de contexto histórico
Al inicio de los ordenadores, solo había líneas de comandos para comunicarnos con ellos. Bell Telephone lanzó en 1969 V1 sobre UNIX Timeshare System. UNIX tenía la shell sh que era la única forma de comunicarse con el ordenador.
Así fue hasta 1973, cuando Las GUI fueron desarrollados en el Centro de Investigación de Xerox en Palo Alto (Palo Alto Research Center, PARC).
Tiempo después, Apple pagó para estudiar la idea, que finalmente se concreto en su GUI.
El MIT desarrolla una GUI para Unix en 1986, X.
El sistema XFree86 de Linux se desarrolló en 1996, una implementación libre del original X, al que homenajea en el nombre.
Bienvenida a BASH
Bash (Bourne-again shell) es a la vez un programa que interpreta órdenes y un lenguaje de programación. Es la shell POSIX que viene por defecto en la mayoría de las distribuciones.
Se trata de un acrónimo recursivo y juego de palabras –una práctica habitual en el movimiento del software libre– que significa "Shell vuelta a nacer", en un homenaje a uno de los primeros intérpretes de Unix Bourne Shell, escrita por Stephen Bourne en 1978 para Unix v.7 (Bell Labs). Brian Fox escribe Bash para GNU en 1987.
Ventajas de la línea de comandos
- Ahorras tiempo, muuuuucho tieeeeempo
- Te ofrecen una alternativa a las GUI.
- Te acercan más a cómo funcionan los sistemas POSIX.
- Funcionas con atajos compartidos.
- Te preparan para la programación.
- Aprendes otra forma de hacer las cosas.
- Te empodera.
¿Cómo empezamos?
Necesitamos un programa que emula la terminal.
GNU/Linux
Abrimos la terminal. Entiendo que si tienes GNU/Linux, sabes hacer esto, pero si no, basta con buscar terminal entre los programas que tenemos instalados.
MacOSX
Lxs usuarixs de MacOSX lo tienen aparentemente más fácil dado que tienen un programa llamado Terminal (Utilidades –> Terminal) que es un buen comienzo. En versiones anteriores de MacOSX puede haber problemas o inconvenientes, ya sea porque no esté activado XCode o porque sea difícil hacerlo.
Windows
Aunque versiones modernas –Windows 10– proveé una terminal, lo haremos con un programa llamado Cygwin que ofrece una completa emulación de terminal POSIX en Windows que a la postre puede resultar incluso más fácil de usar que la de Mac.
Cygwin
Cygwin es una emulación de la terminal UNIX en Windows.
Aunque este es un paso obligatorio para lxs usuarixs de Windows, el resto debe atender pues se explican conceptos que nos van a resultar útiles en otros momentos del curso.
Instalación
Hemos de hacer 4 pasos:
- Descarga del programa.
- Instalar apt-cyg y con ello el resto de paquetes con los que queremos trabajar.
- Instalar
nanocomo editor por defecto en vez devi. - Cambiar la variable
db_homepara acceder a la estructura de directorios de Windows.
Salvo la descarga del programa en sí, el orden de las siguientes tareas responde a nuestros intereses. Lo explicamos.
Instalar paquetes
La consola viene con un conjunto de paquetes básicos. Para usar más paquetes, en el momento de la instalación
del setup, tenemos que elegir los paquetes.
Instalamos nano porque necesitamos un editor de textos en la consola, un editor de textos CLI que nos aporta
velocidad y precisión. Y necesitaremos más.
Una vez que lo instalamos, empezamos a utilizar Cywgin. Pero, ¿qué pasa si quermeos otro programa? Que hemos de cerrar Cywgin y volver a correr el instalador.
Podrías pensar que "¿por qué no instalar todos de una sola vez?", porque es una mala práctica, no tiene sentido y ocuparía muchísimo. Es como si para consultar un libro en una biblioteca tuvieras que descargarte todos…
Para facilitar este proceso utilizaremos apt-cyg, que es un gestor de paquetes –programas– para cygwin.
Algunos paquetes interesantes
- nano, editor de texto.
- git, para trabajar con git, software de control de versiones.
- imagemagick, para manipular imágenes.
- emacs, editor de texto.
- python, para trabajar con Python.
- R, para trabajar con R.
- perl, para trabajar con perl.
- ruby, para trabajar con ruby.
- tesseract, herramienta de reconocimiento óptico de caracteres (OCR), con los paquetes en inglés y español dado que son los idiomas más habituales.
- grep, para realizar búsquedas en el texto.
- pdfgrep: para realizar búsquedas en texto de pdfs.
- sgrep, para realizar búsquedas de texto en documentos SGML, XML o HTML.
- awk y gawk, para procesar texto.
- sed, para editar flujos de texto.
- qpdf, para transformación de PDF
- xpdf, para visionar y otras operaciones con pdf
- odt2txt, para pasar un odt a txt.
- xlsx2csv, para pasar un xlsx a csv.
- p7zip, archivar y comprimir datos.
- gzip, compresor de datos
- unzip, descompresor de datos
- zip, compresor de datos
- lynx, visor web
- links, visor web
- curl, transferencia de archivos multiprotocolo
- wget, descargar archivos de la web
- less, paginador, similar a more
apt-cyg
apt-cyg es un gestor de paquetes de Cygwin que funciona en línea de comandos. El nombre proviene de ser como un apt para Cygwin. Un APT (Advanced Package Tool) es un conjunto de herramientas para manejar los paquetes –programas– de los sistemas Debian GNU/Linux. Se ha hecho muy popular su funcionamiento y otros sistemas operativos lo han imitado porque permite:
- Instalar programas.
- Desinstalar programas.
- Actualizar programas.
- Resolver dependencias de los programas de forma automática.
Para instalarlo, tal como cuentan en su página web:
lynx -source rawgit.com/transcode-open/apt-cyg/master/apt-cyg > apt-cyg install apt-cyg /bin
Cerramos Cygwin y volvemos a abrirlo.
Ahora ya podremos instalar un editor como nano como sigue:
apt-cyg install nano
De su ayuda, vemos el listado de opciones –argumentos– que tiene:
install- para instalar paquetes.
remove- para borrar paquetes.
update- descarga una copia de la lista de paquetes del servidor.
download- descarga los paquetes del servidor pero no los instala ni actualiza.
show- muestra información del paquete.
depends- muestra el árbol de dependencia de un paquete.
rdepends- produce un arbol de paquetes que dependen de ese. Produce a tree of packages that depend on the named package.
list- busca en los paquetes instalados coincidencias con esa expresión regular.
listall- buscará cada paquete en el listado de paquetes por coincidencias con esa expresión regular.
category- muestra todos los paquetes que forman parte de una categoría.
listfiles- lista los archivos que pertenecen a un paquete. Se pueden especificar varios archivos.
search- busca por paquetes descargados propietarios de uno o varios archivos.
searchall- busca en cygwin.com información sobre los paquetes. El objetivo es un archivo y
searchalldevolverá los paquetes que contengan ese archivo. packageof- seguido de archivos o instrucciones, localiza paquetes que los contiene.
Cambiar la home de Cygwin
Por defecto, la home del usuarix de Cygwin es el directorio de instalación del programa.
Para disfrutar de Cygwin y acceder a todo el disco, debemos
modificar la variable db_home en /etc/nsswitch.conf con nuestro editor nano:
nano /etc/nsswitch.conf
Y escribimos:
db_home: windows
O de forma equivalente:
db_home: /%H
Tened en cuenta que en los archivos de configuración, la almohadilla # que aparece al principio de línea
significa que la línea está comentada, es decir, que no la va a leer el programa que quiera leerla para hacer
algo.
Así que os pueden quedar varias líneas comentadas, incluso contad lo que habéis hecho en una línea comentada, para que cuando volváis a este archivo sepáis por qué esta línea es así:
Ahora modifico la línea de la variable db_home
De esta última manera puedes interpretar el esquema y hacer que estén
dentro del subdirectorio cygwin, por ejemplo:
db_home: /%H/cygwin
Si a alguien no le funciona, puede proponer este otro método que proponen en página:
mkpasswd -l -p "$(cygpath -H)" > /etc/passwd
Comandos de Cygwin en la consola de Windows
Esto sería un plus, no lo vimos pero podría hacerse según este blog.
En las propiedades del sistema, en la columna izquierda pincha en propiedades de sistema avanzadas para abrir la ventana de propiedades.
En la pestaña de avanzados, pincha en las variables de entorno abajo. Busca la variable path y pincha en editar. Al final, añadimos la localización de Cygwin:
;C:\Cygwin\bin
Nótese el punto y coma para separarlo de los valores anteriores.
Pincha en OK y cierra la ventana. En el prompt de windows ya puedes ejecutar comandos UNIX.
Configuración de editor por defecto
Cuando editamos un archivo de configuración, por ejemplo de git,
el programa que utiliza por defecto es vi, complicado pero no
imposible (manual en inglés y español).
Si os mola el rollo vi, sería mejor instalar vim (manual).
En este caso vamos a modificarlo por nano. Para ello, editaremos desde el propio nano el archivo .bashrc
del directorio de Cygwin o de la terminal y pondremos:
export VISUAL=nano export EDITOR="$VISUAL"
Algunas utilidades
Interrumpir un comando
Para interrrumpir el curso de un comando, se puede pulsar a la vez las
teclas de Ctrl y c, es decir, C-c
Ctrl + c
Para que esto no suponga un lío, lo habitual es presionar primero la letra
Ctrly, sin soltarla, pulsarcuna vez. Luego soltar en orden inverso, primero lacy luegoCtrl.
Limpiar la línea
Para limpiar la línea con algo que hemos escrito y podríamos borrar
con la tecla de Backspace, podríamos pulsar la combinación de teclas
C-u.
Ctrl + u
Salir de la terminal
Se puede salir de la sesión con el comando exit o con la combinación
de teclas C-d.
Aliases
Esto fue algo que citamos pero que no hicimos, si alguien quiere adaptarlo a sus necesidades, bienvenido sea.
Se pueden hacer alias de los comandos e incluirlos en .bashrc. Por ejemplo:
Un alias de ls para que siempre que lo invoquemos haga ls -aF --color:
alias ls='ls -aF --color=always'
O un comando nuevo, por ejemplo ll, que lanza ls -l:
alias ll='ls -l'
Podemos renombrar un comando, como por ejemplo que grep sea search:
alias search=grep
O que al escribir .. subamos un directorio con cd ../:
alias ..='cd ../'
Pros y contras: hay personas que han personalizado tanto su consola que luego se van a otra y no se apañan. Conviene mantener un equilibrio entre ventajas e inconvenientes.
Comandos como explorador de archivos
whoami
Dice cuál es la cuenta de usuarix que estás empleando:
whoami
ls
Lista los archivos del punto en el que nos encontramos. Viene del inglés list. Si lo lanzamos sin argumentos, obtendremos un listado de los archivos y directorios que contiene ese directorio:
ls
ls [opciones] lista los archivos del punto en el que nos encontramos.
-a, lista todos los archivos.-l, lista en formato largo
Para emplear argumentos, utilizaremos la estructura:
ls -a
Si queremos saber la información de cada archivo y directorio, lo
haremos con la opción -l:
ls -l
pwd
pwd es el acrónimo de print working directory o muestra por
pantalla el directorio de trabajo actual.
Es decir, imprime la ruta absoluta del sistema donde nos encontramos.
pwd
touch
Con touch [archivo], creamos archivo vacío. Podemos usar una extensión o no, a bash le va a dar igual.
touch archivo-para-borrar
Cuando estoy probando, pongo ese tipo de nombres para saber claramente que lo podría borrar ya que si no lo hago inmediatamente, igual más tarde no sé de qué iba.
Ojo de no utilizar mayúsculas, caracteres que no sean ASCII –los ingleses– o espacios en blanco. Para separar palabras, podemos usar los guiones medios –los prefiero a los bajos por cuestiones prácticas, aunque en realidad se han utilizado más los guiones bajos o underscores– o la nomenclatura camelCase (lower, para que la primera palabra empiece por minúsculas.)
file
Este comando permite saber qué tipo de formato es el de cualquier archivo.
Así, si hacemos file sobre archivo-para-borrar, nos dirá:
archivo-para-borrar: empty
empty, vacío.
Si vemos un archivo con terminación txt o el .bashrc que hemos editado antes, dirá otra cosa:
/home/flow/.bashrc: ASCII text
mkdir
Para crear un directorio, usamos mkdir, make directory. Si luego queremos ir a este directorio, tendremos
que usar el comando cd.
cd
Con cd cambiamos de directorio. Viene de las iniciales del inglés
change directory. Si lo lanzamos sin argumentos vamos a nuestro espacio home definido en la variable de entorno HOME.
Para cambiar de directorio, podemos elegir la ruta absoluta o la relativa.
En sistemas *Unix, como son GNU/Linux o MacOSX, la ruta absoluta empieza por una barra / que sería la raíz
del sistema, como el
tronco del árbol de donde salen las ramas que son las distintas carpetas. Hay una jerarquía. Cada
carpeta/directorio se separa con una barra /.
En los sistemas Windows, la raíz es C:\. Las carpetas o directorios se separan con la barra invertida \.
cd [ruta]
- Atajos de rutas
cd, vamos a la home del usuariocd ., vamos al directorio en el que estamos.cd .., vamos al directorio superiorcd ~, vamos al directorio home del usuario.cd -, vamos al directorio donde estábamos antes.
Con esos atajos también podemos construir rutas, por ejemplo, con
cd ~/Documentosvamos al directorio Documentos del usuario con el que estamos (en un ordenador con GNU/Linux)cd [ruta], change directory, cambia al directorio elegido. Podemos escribir la ruta absoluta o bien con atajos:cd, vamos a la home del usuariocd ., vamos al directorio en el que estamos.cd .., vamos al directorio superiorcd ~, vamos al directorio home del usuario.
Con esos atajos también podemos construir rutas, por ejemplo, con
cd ~/Documentosvamos al directorio Documentos del usuario con el que estamos.
cp
Con cp copiamos archivos y/o directorios.
cp [opciones] [origen] [destino]
- Con
cp -rcopia los directorios recursivamente - Si queremos copiar varios archivos/directorios en un directorio, el último que ponemos es el destino.
mv
Con mv un archivo o directorio completo. También sirve para
renombrar, aunque para esto tenemos a rename.
mv [origen] [destino]
env
Si queremos ver o saber qué variables maneja el sistema, podemos verlas con el comando env.
env
Para ver una en concreto, usamos echo, que es un comando que nos devuelve lo que le pidamos. En este caso,
le pedimos que nos devuelva una variable, por ejemplo, de configuración del aspecto del prompt de la línea de
comandos:
echo $PS1
Con el carácter reservado de bash $ llamamos a una variable y con PS1 a esa en concreto.
Miscelánea
Buscadores
- duckduckgo.com
- startpage.com
- searx, https://asciimoo.github.io/searx/
- uno francés.
Segunda sesión
Repaso de la primera sesión
Viene una persona que no vino el primer día y además contamos con un posible nuevo compañero.
Operadores de búsqueda
Hemos tocado los operadores de búsqueda de soslayo, pero os invito a explorarlos más para ser más eficaces en el apartado la Web como fuente de datos del recopilatorio de herramientas de scraping que tengo en Github.
El ejemplo que vimos fue:
site:blog.infotics.es editor de textos
Donde hago una búsqueda sobre mi blog para encontrar un artículo en el que hablo sobre editores de texto.
Editor de textos
Del artículo que os señalo, resumo las características que debe tener cualquier buen editor de texto:
- Herramienta de búsqueda y reemplazo de texto
- Que se combina con el uso de expresiones regulares
- Indentado de texto, para los bloques de código o el código.
- Resaltado de sintaxis, para colorear las distintas partes del documento según de qué se trata.
- Modo esquema, para visualizar rápidamente documentos complejos.
- Ejecución de código, para que los bloques de código produzcan texto.
Aunque vimos varias opciones de editores GUI al final nos decidimos por nano.
Repaso de la instalación de apt-cyg en Cygwin
El software apt-cyg se utiliza en Cygwin para la gestión de paquetes -comandos, programas- en Cygwin.
Para instalarlo, en la página web nos sugieren hacerlo copiando y pegando en la terminal -Cygwin- esta línea:
lynx -source rawgit.com/transcode-open/apt-cyg/master/apt-cyg > apt-cyg
Como muchxs no teníais lynx, lo descargamos corriendo de nuevo el instalador de Cygwin.
En el caso de Mac, conviene instalar brew.
Brew
Se puede descagar de brew.sh
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Entonces:
brew install wget
O bien:
brew cask install firefox
lynx
Volviendo al manual de Cywgin, ejecutamos en la consola la siguiente línea
lynx -source rawgit.com/transcode-open/apt-cyg/master/apt-cyg > apt-cyg
Luego le damos a Enter.
Esta línea hace varias cosas:
- Utiliza el comando
lynx, que es un navegador CLI, para ver la página del código de apt-cyg. - Con la opción -source, lo que hace es mostrar el código fuente de la página, por lo que así tenemos lo que
queremos, el código del comando
apt-cyg. - Luego emplea el operador de bash
>(luego explicamos esto más) para enviar ese código a un archivo que creamos en ese momento que llamaremosapt-cyg.
A continuación, instalamos en nuestro cygwin ese comando en el directorio/carpeta donde se encuentran los
programas –los binarios, los ejecutables–, que es /bin:
install apt-cyg /bin
Cerramos Cywgin y volvemos a abrirlo.
A partir de aquí, ya podremos utilizar apt-cyg para instalar comandos.
Una de las primeras cosas que hicimos fue modificar el archivo /etc/nsswitch.conf para que la home de
Cywgin fuera la de Windows y no la propia de Cygwin.
Para ello, usamos nano:
nano /etc/nsswitch.conf
Y vemos esto:
# /etc/nsswitch.conf # # This file is read once by the first process in a Cygwin process tree. # To pick up changes, restart all Cygwin processes. For a description # see https://cygwin.com/cygwin-ug-net/ntsec.html#ntsec-mapping-nsswitch # # Defaults: # passwd: files db # group: files db # db_enum: cache builtin # db_home: /home/%U # db_shell: /bin/bash # db_gecos: <empty> db_home: windows db_home: /%H
En este archivo, he añadido esas dos líneas al final. Nótese que no están con una almohadilla al principio de línea, lo que indica que no están comentadas.
Grupo de Telegram
Hemos creado un grupo de Telegram para intercambiar este tipo de archivos y ser más operativos en clase.
Poco a poco ha ido añadiéndose todo el mundo.
Símbolos escapados
Los símbolos o caracteres que se escapan son aquellos que utiliza el lenguaje que estemos utilizando para sus propias órdenes.
Por ejemplo, en HTML hay que escapar el carácter & ya que es el carácter con el que se nombran las entidades HTML:
&
API de BASH
BASH tiene una API muy sencilla y muy potente. Una API (Application Programming Interface o interfaz de programación de la aplicación) es el código para comunicarnos con un programa determinado. En este caso, con BASH.
Cuando ejecutas un comando en la shell, se producen tres procesos:
- La salida del comando, que es lo que devueve el comando, normalmente en la terminal, llamada STDOUT por STandarD OUTput o salida estándar.
- La entrada de datos, argumentos o comandos es lo que se conoce como STDIN por STandarD INput.
- La salida de errores, si ha dado errores, que se llama STDERR por STandarD Error o error estándar.
Figure 1: Diagrama de funcionamiento de STDIN, STDOUT y STERR. Fuente: Wikipedia: Esquema de POSIX y C de entrada estándar. Licencia Dominio Público.
Atajos de Bash
| Comando | Descripción | Ejemplo |
|---|---|---|
| C-d o exit | Cierra la ventana | salida |
| cd | Cambia el directorio | cd test |
| pwd | Mostrar el directorio actual | cd (Windows) o pwd (Mac OS / Linux) |
| ls | Lista directorios/archivos | ls . |
| cp | Copia de archivos | cp ruta-origen ruta-destino |
| mv | Mueve archivos | mv ruta-origen c:\test\test.txt c:\windows\test.txt |
| mkdir | Crea un nuevo directorio | mkdir testdirectory |
| rm | Eliminar un archivo | rm ruta-archivo |
| rm -rf | Fuerza la eliminación de un Directorio de forma recursiva | rm -r ruta-directorio |
Comodines
Los comodines permiten usar valores conocidos con valores comodín.
Hay tres operadores:
*, para cualquier número de caracteres.?, para un carácter.[x-y], para un rango.
*
Podemos listar todos los csv con el comodín *, ya que puede haber
archivos con un carácter o varios.
ls *.csv
De esta manera listaremos todos los archivos csv, pero también #+BEGIN_SRC sh :output org
ls *.csv
#+END_SRC
| black_corrupcion.csv |
| black-is-black_backup.csv |
| black-is-black.csv |
?
El comodín ? sirve para solo un carácter, cualesquiera. Por ejemplo,
si tuviéramos archivos que solo difieren en un carácter, podemos
listar ambos.
Imaginemos que tenemos archivos 1.pdf, 2.pdf, 3.pdf,
etc. Podríamos listarlos con el comodín ?:
ls ?.pdf
[]
El comodín corchetes cuadrados o [] permite buscar rangos de números
o letras.
si queremos buscar en el csv tanto CLESA como BLESA, podemos
escribir:
grep [B-C]LESA black-is-black.csv | wc -l
Proyectos interesantes referenciados
- De Civio, España en llamas
Software hablado
- apt-cyg:
- trackula: https://addons.mozilla.org/en-US/firefox/addon/trackula/
Fun-da-men-tal?
How (not) to be a danger to yourself and others using the command line:
Taller de la conferencia de periodismo de datos de EE.UU. (NICAR) de 2013:
Harkening back to an earlier era of computing, the command line can easily seem like magic. Incantations are learned by rote, passed on by word of mouth from user to user, or written into arcane and impenetrable documentation. But live in fear no more! We will illuminate its nature and bind it to our use, navigating computers, manipulating files, and opening a comprehensible gateway to a world of pro-user and developer tools. Attendees should bring their laptops and be prepared to discover the Linux or Mac command line. (Note: Windows users may also learn transferable skills)
¿Puede un periodista usar la línea de comandos?
Esta sesión comienza con la explicación de un conjunto muy básico de comandos con los que nos moveremos por el sistema de ficheros. Progresivamente iremos viendo cómo se pueden usar otros comandos para hacer el tratamiento de los datos que podemos tener en nuestro sistema de ficheros, y como podemos automatizar muchas de estas tareas, tan necesarias cuando uno tiene que hacer preprocesamiento de datos.
Introducción a la línea de comandos
Introducción a la línea de comandos de Django Girls. Django es un framework para el desarrollo web en Python. Vaya, ¿si se sabe de Python para qué se necesita Bash? Precisamente.
Tercera sesión
URL y más allá
Si queremos interactuar con una web, hacer una página, hacer web scraping, en definitiva, entender algo de la web, debemos saber qué es una URL.
Qué es una URL… el acrónimo significa Uniform Resource Locator, localizador de recursos uniformes. Esto ya da algunas pistas:
- Es un localizador, luego seguirá alguna nomenclatura.
- Localiza recursos, que es como se denominan genéricamente los archivos, documentos, páginas web, direcciones de correo electrónico o cualquier cosa electrónica: recursos.
- Es uniforme, luego un localizador no choca con otros.
Veamos un ejemplo de URL, la web del diario británico The Guardian:
https://www.theguardian.com/international
Esta dirección URL se descompone en:
- Protocolo: https
- Separación protocolo-dominio: ://
- Dominio completo: www.theguardian.com
- dominio mínimo: theguardian.com
- .com: TLD
- theguardian: el proyecto
- www: subdominio
- dominio mínimo: theguardian.com
- /international : estructura de ficheros/contenidos
Repaso de atajos
Ordenador
Aunque utilizamos teclados QWERTY –por la disposición de las teclas–, cada ordenador dispone otras teclas o caracteres en uno u otro lugar. O viceversa, aunque hay diferencias, hay un gran teclado común que podemos explotar si sabemos algo de mecanografía e incorporamos algunas otras teclas/caracteres.
Sistema operativo
Cada sistema operativo e incluso cada versión del sistema utiliza unas u otras formas de acceder al contenido. Debemos familiarizarnos con ello para mejorar la productividad.
Aplicaciones
También las aplicaciones tienen sus particularidades, pero hay unas normas de accesibilidad a las aplicaciones que sirven para que nos apoyemos en el teclado como vehículo de nuestra interacción con el ordenador/aplicación. Explotar esta relación hará que seamos más eficientes.
Navegador
Como cualquier otra aplicación, se puede aprovechar esa accesibilidad. Pero además, traerá sus propios atajos o shortcuts. Una búsqueda apropiada en nuestro buscador favorito nos devolverá por seguro alguna referencia interesante. Merece la pena que empleemos algo de tiempo para con las aplicaciones que más a menudo utilizamos.
Web
El contenido web en sí también cumple unos parámetros de accesibilidad, aunque en este caso es probablemente en el que menos se cumplen, en general. Una buena forma de probarlo es utilizar el tabulador para pasar del texto de un enlace a otro. Si la página está bien realizada, tendrá teclas de acceso al contenido o accesskeys.
Open Refine
Open Refine lo llaman la navaja suiza del análisis de datos. Nos permite explorar de una forma muy sencilla grandes archivos CSV, pero también realizar transformaciones de datos o incluso de formatos.
Descarga de Open Refine:
http://openrefine.org/download.html
En esta sesión no pudimos avanzar por las distintas situaciones de cada uno de los equipos. Fundamentalmente:
- Actualización de la máquina virtual de Java.
- Aceptación del uso de aplicaciones "no seguras" por parte de MacOSX.
Manual de Open Refine:
Para quienes lo vayan consiguiendo, les recomiendo echar un vistazo a mis apuntes sobre Refine.
Personalización de la línea de comandos
Esto no lo pudimos realizar juntxs pero os dejo este enlace por si queréis probarlo.
Análisis de datos
Hemos empezado bajándonos este archivo de mercados de barrio del portal de datos del ayuntamiento de Madrid. Pero como no era muy grande, hemos pasado al tutorial de Óscar Corcho ¿Puede un periodista usar la línea de comandos?, donde compartía un dataset de comercios de Madrid.
Como no lo encuentro en su lugar de origen, en el portal de datos abiertos del Ayuntamiento de Madrid, tiro de biblioteca y lo comparto por aquí, pero lo vamos a bajar con curl:
curl -L https://nube.egelesta.net/s/PnCwxyeG8rr23oL/download > data/comercios-madrid.csv
Lo ponemos en la carpeta data
He encontrado este otro archivo PDF que sobre los microdatos de este archivo.
Para descargarlo, podemos emplear curl:
curl -O https://datos.madrid.es/FWProjects/egob/contenidos/datasets/ficheros/Comercio_CensoLocalesActividades/ConceptosFundamentalesCLA.pdf
Antes de pasar a las operaciones básicas de de exploración del archivo, detengámonos en lo que hemos hecho y tres comandos con los que nos podemos descargar archivos:
Descarga de archivos
En la anterior sesión usamos lynx para descargarnos el programa apt-cyg. En esta ocasión vamos v ver otros
dos comandos, hechos más a propósito para esa tarea:
curl
curl es una herramienta para transferir datos de o hacia un servidor a través de uno de los protocolos
soportados. Nos interesa porque soporta tanto HTTP como HTTPS. Para descargarnos un archivo sería:
curl https://nube.egelesta.net/s/PnCwxyeG8rr23oL/download > data/comercios-madrid.csv
De esta manera, redirigimos la salida estándar al archivo deseado. También podríamos haberlo hecho con curl -o nombre-archivo url:
curl -o data/comercios-madrid.csv https://nube.egelesta.net/s/PnCwxyeG8rr23oL/download
O -O si no quisiéramos cambiar su nombre:
curl -O https://nube.egelesta.net/s/PnCwxyeG8rr23oL/download
Si quisiéramos descargar de una sola vez varios archivos, podríamos poner sus URLs una tras otra después de la
opción -O antes de cada URL:
curl -O url1 -O url2 -O url3
Otras dos opciones interesantes son, la de -C para continuar una descarga que se paró, y la de -z para
descargar de nuevo un archivo si se ha modificado en una fecha dada.
curl -z -21-dic-11
wget
wget es otro programa creado para descargar archivos. La estructura sería la siguiente:
wget -O ruta-local URL
Con la opción -O damos nombre al archivo que descargamos.
- Descargar una lista de archivos
Una opción muy interesante con wget es la opción
-i, que permite descargar archivos que estén en una lista en un archivo de texto. Por ejemplo, los cuatro archivos CSV de locales de Madrid son:$ cat descarga.txt https://datos.madrid.es/egob/catalogo/209548-148-censo-locales-historico.csv https://datos.madrid.es/egob/catalogo/209548-151-censo-locales-historico.csv https://datos.madrid.es/egob/catalogo/209548-149-censo-locales-historico.csv https://datos.madrid.es/egob/catalogo/209548-150-censo-locales-historico.csv
- De forma recursiva
Con la opción
-rdescarga un sitio de forma recursiva y crea los directorios tal como están:wget -r url
- De forma recursiva, a un solo archivo
wget -nd -r url
- Todos los archivos de cierto tipo
wget -A "*.xlsx" -r url
- Ignorar los archivos de cierto tipo
wget -R "*.exe" -r
- Bibliografía
lynx
Fue de los primeros comandos que conocimos al descargar desde Windows apt-cyg. Se trata de un navegador web en
línea de comandos pero se puede utilizar para descargar el código fuente de una página, en estos casos un
archivo csv, con la opción --source. Además, debemos llevar la salida estándar a un archivo para guardarlo.
lynx --source https://nube.egelesta.net/s/PnCwxyeG8rr23oL/download > nombre-archivo
Exploración de archivos
wc
Con wc (word count) podemos saber cuántas líneas tiene, cuántas palabras, cuántos caracteres o cuánto pesa:
El esquema de uso sería:
wc [opciones] archivo
Y las opciones son:
-l, cuenta líneas-c, cuenta bytes-m, cuenta carácteres-w, cuenta palabras
Me interesa saber cuántas líneas tiene:
wc -l data/comercios-madrid.csv
file
Qué tipo de archivo es, para ello usamos file:
file data/comercios-madrid.csv
du
Para saber cuánto pesa de forma legible, usamos du con las opciones -sh:
du -sh data/comercios-madrid.csv
Donde:
-h, pone los datos de forma comprensible.-s, resume.
head
Con head vemos la cabecera del archivo, las diez primeras líneas o filas:
head -1 data/comercios-madrid.csv
Aquí vemos algunas cosas:
- Que la primera línea es la cabecera del
*SV, lo cual está bien. - Que los valores de las celdas están entrecomillados para evitar problemas con lo que contienen.
- Que el separador o delimitador de cada valor es el punto y coma
;. - Que al final de línea hay un símbolo
^M, que merece punto aparte. - Que los caracteres con tildes no se ven correctamente, que merece punto aparte y que tiene que ver con la codificación del archivo que veíamos antes que era
ISO-8859-1en vez deISO-8859-15oUTF-8.
Qué es "^M"
Tal como cuentan en stackoverflow, está causado por ser el carácter de final de línea de DOS/Windows. El comando dos2unix resuelve el tema:
dos2unix data/comercios-madrid.csv
Volvemos a pasar head, en esta ocasión solo con 3 líneas con la opción -3 para ver si ha funcionado:
head -1 data/comercios-madrid.csv
Codificación del archivo
Dado que el archivo no es ISO-8859-15 o UTF-8 sino ISO-8859-1, no vemos los caracteres con tilde.
Para ello, pasamos el archivo a UTF-8 con iconv:
iconv -f ISO-8859-1 -t UTF-8 data/comercios-madrid.csv > data/comercios-madrid-utf-8.csv
Otra opción es hacerlo con uconv, que se encuentra en el paquete ruby-uconv, y que Jon Avrach señala como más potente que iconv para grandes archivos:
uconv --from-code ISO_8859-1 --to-code UTF8
Veamos si ahora se ven esos caracteres:
grep -rn Hostelería data/comercios-madrid-utf-8.csv | wc -l
Se encuentran 17016, luego se "ven" ;-)
tail
Con tail vemos las diez últimas líneas/filas, a no ser que le pongamos la opción -n, donde n es el número de líneas/filas que podemos ver.
tail -3 data/comercios-madrid-utf-8.csv
split
Una opción que planteaba Óscar era, dadas las dimensiones del archivo, partirlo en trozos con split:
split -l 2000 data/comercios-madrid-utf-8.csv
Lo cual generará 76 ficheros, con nombres xaa, xab, etc., cada uno de ellos con 2000 líneas (excepto el último).
Para moverlos todos a un directorio, primero lo creamos:
mkdir data/comercios-split
Y luego los movemos:
mv x* data/comercios-split/.
grep
Para hacer búsquedas sobre el texto.
Imaginemos que queremos saber cuántos locales de 100 Montaditos hay:
grep -i 'montaditos' data/comercios-madrid-datos-txt.csv |wc -l
La opción -i de grep es para indicarle que no discrimine por mayúsculas o minúsculas, que encuentre todas.
De estos 47 locales en Madrid capital, nos gustaría saber cuántos están en el distrito centro:
grep -E 'MONTADITOS' data/comercios-madrid-datos-txt.csv | grep -Ec 'CENTRO'
Un total de 14 locales, casi un tercio del total.
14
sed
sed -n '5p' ruta-archivo
Cuántas columnas tiene
Para extraer otras columnas, podemos ayudarno si sabemos cuántas columnas tiene. Para ello, dado que sabemos que utiliza el delimitador ;, podemos contar cuántas veces aparece en una línea:
head -1 data/comercios-madrid-utf-8.csv | fgrep -o ";" | wc -l
La opción -o de fgrep busca solo esa cadena.
En esta web, he encontrado esta opción con sed:
head -1 data/comercios-madrid-utf-8.csv | sed 's/[^;]//g' | wc -c
Utiliza sed para borrar de la primera línea todo menos los punto y coma, y luego los cuenta. Más adelante vemos un poco de sed.
cut
Con cut podemos seleccionar columnas del archivo. Imaginad que nos interesan las columnas -los campos- número 3, de distrito; 5, de barrio; 32, de rótulo; 34, de sección; 36, de división; y 38, de epígrafe:
cut -f 3,5,32,34,36,38 -d ';' data/comercios-madrid-utf-8.csv > data/comercios-madrid-datos-txt.csv
Si os devuelve el error: illegal byte sequence, como ha ocurrido en varios MacOSX, se deben ejecutar estos comandos, primero uno y luego el otro:
export LC_CTYPE=C
export LANG=C
Y volver a ejecutar cut.
Si hubiéramos querido campos seguidos, podríamos haber combinado las comas para separarlos con el guión para los rangos. Por ejemplo, si quisiéramos los campos del primero al quinto más el décimo:
cut -f 1-5,10 -d ';' data/comercios-madrid-utf-8.csv > data/comercios-1-5-10.csv
Se pueden seleccionar todos los campos menos uno, dos y/o un rango:
cut -d ';' --complement -s -f 7-38
De esta forma, no tendremos los campos del 7 al 38.
También se puede cambiar el delimitador con la opción --output-delimeter:
cut -d ; --complement -s -f 3-5,6-33 --output-delimeter ',' data/comercios-madrid-utf-8.csv
Flujo de texto
sed
Se utiliza para modificar el texto.
- Buscar y reemplazar
Por ejemplo, de
100 MONTADITOSquiero convertir100enCIEN:sed s/100/CIEN/ ComerciosMadrid.csv
Si hay algún carácter en blanco y lo tenemos identificado, como en el caso de "CIEN MONTADITOS ":
sed s/100 MONTADITOS/CIEN MONTADITOS/ ComerciosMadrid.csv
- Eliminar línea
Se puede borrar las líneas que contengan algo:
sed /patrón/d archivo
- Para actualizarlo
Con la opción
-i:sed -i /patrón/d archivo
Cuarto día
- Repaso: ¿lo dejamos para el jueves?
- Open Refine: ¿lo dejamos para el jueves?
- Github: crear nuestro primer repositorio.
- Web scraping: si da tiempo, empezamos.
Dudas
Conocer distintos tipos de formatos de (intercambio de) datos
Fundamentalmente hay tres familias de formatos de datos, que también son formatos de intercambio de datos:
- *SV, valores separados por algo.
- *ML, lenguajes de marcado.
- JSON, JavaScript Object Notation, notación de objetos JavaScript.
- *SV
El asterisco indica cualquier carácter mientras que
SVsignifica valores separados por. Los caracteres más comunes son el tabulador y la coma, que hacen los formatos TSV (tab separated values, valores separados por tabulador) y CSV (Comma Separated Values, valores separados por comas.El formato CSV es el RFC4180 y el TSV IANA-TSV (según aparece en SPARQL 1.1) están soportados por la mayoría de las aplicaciones. Son simples, pesan poco y facilitan el intercambio de datos.
Son formatos abiertos aunque no estandarizados. También presentan problemas con la codificación de caracteres y el indicador de fin de línea.
La elección entre uno u otro, como cuentan en stackoverflow, depende de los datos que haya. Básicamente, si los datos no contienen comas, CSV es una buena elección; en caso contrario y siempre que no tengan tabulación, TSV.
En ambos casos vamos a encontrarnos con problemas con el delimitador de valor, por lo que si aparece habría que indicar que se trata de un carácter más y no un delimitador, lo cual se puede hacer de varias maneras:
- Quitándolos, lo cual no es muy práctico.
- Escapándolos, lo cual es tedioso.
- O la solución más extendida, que es que cada valor se entrecomilla, por lo que se trata como literales. Lo cual puede ser controvertido si hay valores que presentan comillas a su vez
Ventajas y desventajas:
- El CSV es más genérico y más conocido y por tanto puede funcionar mejor en más
escenarios. Por contra, el entrecomillado aumenta el tamaño del archivo y genera también sus inconvenientes.
- El TSV (<TAB> o
\t) no suele presentar el inconveniente del delimitador como es menos conocido pero también lo es el formato.
- *ML
MLse refiere a lenguaje de marcas, una forma de anotar un documento de tal forma que su sintaxis sea distinguible del contenido.Tradicionalmente se han utilizado las marcas para hacer anotaciones al texto, por ejemplo, en las labores de revisión del texto, pero los lenguajes de marcas van más allá, pues también son una estructuración del contenido y de sus distintas partes.
Hay ejemplos de lenguajes informáticos en los orientados a labores de impresión, como troff, TeX o LaTeX.
El nombre ML viene del IBM GML, lengua de marcas generalizadas en el que luego se inspiró SGML, con dos principios:
- El marcado es declarativo, describe la estructura del documento y los atributos, no se preocupa tanto por su procesado.
- El marcado debe ser riguroso, de cara a que se pueda procesar y aprovechar como un sistema de base de datos de documentos.
HTML se basa en -es una instancia de- SGML y XML en HTML. HTML fue construido para la web de documentos y XML se inspiró en esa potencia para realizar un formato de marcas extensible, de cara al intercambio de datos de cualquier aplicación.
Ha tenido una edad dorada en la década de los 2000, incluso Microsoft convirtió sus formatos de datos a formatos basados en XML.
Aunque se usa mucho en aplicaciones comerciales o industriales, en la actualidad ha perdido mucho peso en beneficio de JSON, que es más sencillo y nativo para la web.
- JSON
JSON (JavaScript Object Notation o notación de objeto de JavaScript) es un formato de texto muy utilizado para el intercambio de datos en la Web.
Se analiza con la función
eval().JSON se construye sobre dos estructuras:
- Una colección de pares nombre-valor: object, record, struct, dictionary, hash table, keyed list, o associative array.
- Una lista ordenada de valores: array, vector, list, o sequence.
- Objeto
Un objeto es un conjunto desordenador de pares de nombre-valor. Un objeto empieza con una llave
{y finaliza con cierre de llave}. Cada nombre es seguido por un dos puntos:y los pares nombre-valor son separados por comas,.Ejemplo de objeto:
objeto:{"nombre":"Fulano","nombre":"Mengano"} - Array
Un
arrayo serie es una colección ordenada de valores. El array empieza con un corchete[y termina con un cierre de corchete]. Los valores son separados por comas.serie:["Fulano","Mengana","Zutanito"]
- Value
Un
valueo valor puede ser una cadena de caracteres, un número, un valor nulo, un buleano, un objeto o una serie. Estas estructuras se pueden anidar. - string
Un
stringo cadena es una secuencia de cero o más caracteres Unicode entrecomillados. - number
Un número es un número salvo los octales o hexadecimales.
- Ver un JSON en terminal
python -m json.tool mi_archivo.json
Tipos de datos
En general, tratamos con:
- Números enteros o integers
- Decimales, flotantes o floats
- Cadenas -de caracteres- o strings
- Booleanos: verdadero o falso
- Null: datos nulos
- Otros objetos
Conversión de datos: XML, CSV, XLSX
- Pandoc
Pandoc funciona muy bien como conversor entre formatos de marcas, una auténtica navaja suiza para Markdown, reStructuredText, textile, HTML, DocBook, LaTeX, MediaWiki, TWiki, TikiWiki, Creole 1.0, Vimwiki, roff man, OPML, Emacs Org-Mode, Emacs Muse, txt2tags, Microsoft Word docx, LibreOffice ODT, EPUB o Haddock.
- Code beautify
Code Beautify transforma datos de unos a otros.
- ssconvert
ssconvert es una utilidad en línea de comandos para transformar hojas de cálculo de unos formatos a otros. Forma parte del programa gnumeric, el gestor de hojas de cálculo de GNOME. Puede trabajar entre xls, xlsx, odf, html, LaTeX, PDF y CSV, entre otros.
Con ~ ssconvert –list-exporters~ se puede ver la lista de formatos.
- csv a tsv y viceversa con sed
De csv a tsv, transformamos la
,en tabulador\t:sed 's/,/\t/' archivo.csv > archivo.tsv
De tsv a csv, al revés:
sed 's/,/\t/' archivo.tsv > archivo.csv
- cat y tr
$ cat archivo.csv | tr "," "\\t" > Galton.tsv
- csvkit
csvkit es un conjunto de programas en línea de comandos para convertir o trabajar con CSV. Se pueden convertir XLSX o JSON a CSV, entre otras opciones.
- Open Refine
Se puede utilizar para pasar de un formato a otro. En este ejemplo, se pasa de XML o JSON a CSV o XLSX.
¿Necesita Open Refine conexión a Internet?
No
Selección por fechas en refine y agrupación en Refine
Sí, lo vemos.
Grep es súper útil y lo demás sobra
Para muestra, un botón:
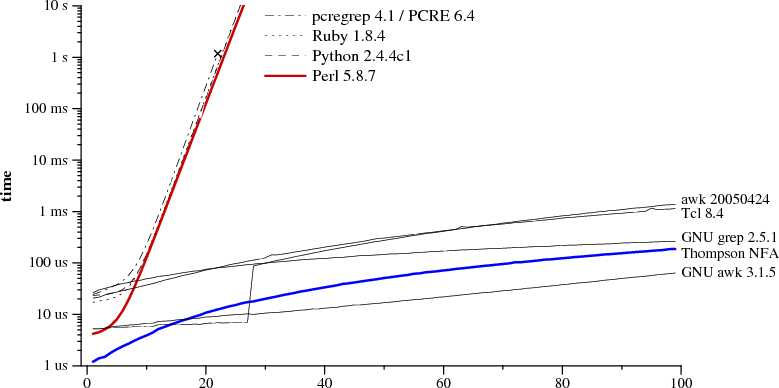
(Citado en esta presentación)
Se muestra el tiempo que emplean distintos lenguajes en búsqueda de patrones de expresiones regulares. grep y awk ganan ampliamente.
¿Y no vamos a ver algún programita que haga gráficos?
Si da tiempo, veremos datawrapper.
Gestión paquetes windows
Si ya te has acostumbrado a apt-cyg para Cygwin, Chocolatey hace lo mismo para Windows, es decir, es un gestor de programas para Windows.
Github
Lo primero que se necesita es tener git instalado, podemos hacerlo con apt-cyg en Cygwin, Brew en Mac o el modo adecuado en las distribuciones GNU/Linux.
Vamos a trabajar con un servicio web remoto que soporta git, Github. Necesitamos una cuenta en este servicio gratuito.
Creamos un repositorio siguiendo el método de línea de comandos.
Para cualquier duda, se pueden consultar mis notas de Github. Seguimos el
Hagamos nuestra propia web
Para ello, hemos de elegir una plantilla de html5up.net. Recomiendo Prollogue, pero elegid la que queráis.
Si elegís Prologue, descargad el zip y descomprimirlo con unzip en el directorio donde queráis poner la web.
Si no tenéis unzip, solo hay que descargarlo.
Aprovecho para recomendar en Windows un programa gráfico de gestión de archivos comprimidos: 7-zip.
Quinto día
Desorden del día
- Repaso de Github
- Repaso de línea de comandos
- Open Refine
- Scraping: web y pdf
Repaso de línea de comandos
seq
Con seq podemos crear una secuencia de números.
seq 1 10000 > data/diez-mil.txt
De esta manera, creamos un archivo txt con 10000 líneas con los números de 1 a 10000.
Sipones un número entre medias es el intervalo. Por ejemplo:
seq 1 100 10000 > data/diez-mil-de-cien-en-cien.txt
Crea un archivo con números de 1 a 10000 cada 100.
Web scraping
Web scraping significa literalmente rascar datos de la web. Por ello podemos pensar que cada vez que queramos información de la web debemos hacer web scraping, y eso no es del todo así.
Web scraping sería, estrictamente, sacar algunos datos, los que precisemos, del conjunto de contenidos que muestran las webs. Esto de rascar no es casual, obedece a que aunque HTML es un lenguaje de marcas estructurado y la web puede simular información estructurada y ordenada, ni esto es siempre así –por malas prácticas voluntarias o involuntarias de quienes producen o publican la información web– ni suele estar accesible al estilo base de datos pública de datos abiertos.
Otra opción, que no es scraping, es utilizar un crawler como nuestra querida wget o el todavía no conocido
httrack y descargarnos todo el sitio para hacer luego una exploración en local.
Simon Holywell propone esta receta con wget:
wget -H -r --level=5 --restrict-file-names=windows --convert-links -e robots=off http://example.org
- Se crea una copia local.
--convert-linksconvierte los enlaces en URLs relativas de tal manera que puede explorarse todo el sitio en local.- Con
--restrict-file-names\=windowsse aseguran nombres de archivo seguros, sin parámetros añadidos.
A continuación jugamos un poco con algunos listados y tablas de distintas urls probando:
- Funciones
importHTML()eimportXML()de Google Spreadsheets - Repaso de
curl,wgetylynx
ImportHTML()
Para esto necesitamos una cuenta de Google y abrir una nueva hoja de cálculo.
Con importHTML() podemos llevar a esa hoja de cálculo los datos de una tabla o de un listado de una página
web. Para ello conviene tener ciertas nociones de HTML.
Los elementos HTML que se ven afectados son table (tabla), ul, ol y dl (listados).
ul, que corresponde a unordered list o lista desordenada, la típica lista donde cada elemento aparece con un punto o un guión.ol, que corresponde a ordered list o lista ordenada, donde los elementos del listado aparecerán ordenados, bien numérica o alfabéticamente, por ejemplo.dl, corresponde con description list, listas de descripcionestable, corresponde con una tabla de datos tabulados.
Construiremos la función IMPORTHTML con la url entrecomillada, separado por punto y coma y entrecomillado el elemento del que queremos sacar la información, bien una lista list o una tabla table, seguido del número de elemento en la página de su mismo tipo, separado por otro punto y coma:
=IMPORTHTML("URL";"list|table";n)
ImportXML()
Una vez que hemos probado importHTML() vamos con importXML(). Si la primera tenía tres argumentos, en esta
segunda solo son dos, pero el segundo puede ser muy simple o muy complejo.
El esquema es:
IMPORTXML("url";"consulta-xpath")
Como vemos, el primer argumento es la URL sobre la que queremos obtener datos y el segundo es la consulta
xpath.
XPATH es el acrónimo de XML Path o ruta XML. Es decir, se trata de identificar los nodos de un archivo
XML. La web son archivos HTML pero al ser renderizados por el navegador crea un DOM (Document Object Model,
modelo de objetos de documento) como un árbol de objetos que puede ser leído por XPATH.
XPATH
Algunos ejemplos:
- "nombre_del_nodo", selecciona todos los nodos con ese nombre
/, selecciona del nodo root.//, selecciona nodos en el documento desde el nodo actual que coincide con la selección, sin importar donde se encuentran.., selecciona el nodo actual.., selecciona el nodo padre del nodo actual.@, selecciona atributos
Se pueden consultar mis apuntes de Scraping. Si queréis aprender web scraping, XPATH es el camino.
- Listado de atributos
Por ejemplo, si queremos obtener el listado de todos los atributos
hrefque contiene el elementoaque corresponde a los enlaces, de la URL, de una página web, haremos:=IMPORTXML("URL";"//a/@href") - Enlaces de una clase
Pero podríamos elegir sólo los enlaces que tienen una determinada clase, lo que haríamos también con XPath de esta manera:
=IMPORTXML("URL";"//a[@class='clase']") - Referencia a celdas
En vez de editar la fórmula completa, se puede poner la URL en una celda, el elemento XPath a buscar en otra y construir la expresión llamando a las celdas:
=IMPORTXML(celda1;celda2)
- Elementos que comienzan con…
La potencia de Xpath es infinita y podemos hacer extracciones de datos muy concretas, como por ejemplo seleccionar solo los elementos que comiencen con una clase específica, como
[starts-withy luego especificar la clase con el atributo@dondeclasses el valor del atributo(@class, 'clase')Si queremos sacar todos los enlaces una URL, después de inspeccionar la página, comprobamos que los enlaces se encuentran en un
divque tiene la claseclase. Construimos esta fórmula deIMPORTXMLIMPORTXML("URL"; "//div[starts-with(@class,'clase')]")Si quisiéramos los enlaces, añadiríamos al final
//@href, ya que el enlace se encuentra en el atributo dea,href=IMPORTXML("URL"; "//div[starts-with(@class,'clase')]//@href")Puede ser que la página no traiga los enlaces absolutos sino que sean relativos, por lo que podemos concatenarlos con la función
CONCATENATE:=CONCATENATE("URL",celda-resultados)Y luego estiramos esta función al resto de las celdas que lo requieran.
- Algunos ejemplos XPath útiles:
//, descarga todos los elementos de html que empiecen con<//a, descarga todos los contenidos del elementoa, los enlaces, de la URL que decidamos.//a/@href, descarga todos los contenidos del atributohrefdel elementoa, que corresponden con la URL del enlace.//input[@type'text']/..=, descarga todos los elementos padre de los elementos de textoinputcount(//p), cuenta el número de elementos que le digamos, en este caso párrafosp//a[contains(@href, 'protesta')]/@href, encuentra todos los enlaces que contienen la palabraprotesta//div[not(@class'left')]=, encuentra todos losdivcuyas clases no seanleft//img/@alt, muestra todos los textos de los atributosaltde las imágenesimg
Más Scraping
- https://blog.scrapinghub.com/2016/10/27/an-introduction-to-xpath-with-examples
- https://stackoverflow.com/questions/7361229/data-scraping-with-wget-and-regex
- http://scraping.pro/xpath-review/
- https://www.joyofdata.de/blog/using-linux-shell-web-scraping/
- https://stackoverflow.com/questions/19098315/httrack-wget-curl-scrape-fetch
Sexto día
Desorden del día
- QGIS
- Plantilla de HTML
- Bash avanzado
QGIS
Repaso Github
Cambiar el editor por defecto
Por defecto, bash y git vienen con el editor vi por defecto. Para cambiarlo, tal como explican en stackoverflow, podemos hacerlo en una o en
ambas.
- core.editor
Para usar
nanoo el editor de texto CLI de nuestra elección, corremos:git config --global core.editor "nano"
La opción
--globales para hacerlo en todo git. Si solo quisiéramos en este repositorio, sería sin esa opción. - nano como editor por defecto
Lo hacemos en dos líneas, con dos variables de entorno:
export VISUAL=nano export EDITOR=$VISUAL
Séptimo día
Desorden del día
- Repaso general
- Dudas
- Documentación
Repaso general
He intentado dar un panorama introductorio lo más profundo posible de varias tecnologías. Aposté por que empezáramos por la terminal para no quedarnos faltos de tiempo y creo que habéis conseguido empezar a controlar la herramienta.
La terminal os va a dar las bases para probar, practicar y aprender lo demás.
Para practicar, y retomando lo que hicimos el otro día, vamos a configurar el editor de texto nano para que sea el editor por defecto de la terminal, de git y además para que muestre resaltado de sintaxis.
Recordad que el resaltado de sintaxis es una de las características fundamentales de un editor de textos, tal como contaba en mi blog.
Si no os acordáis la URL del artículo, podemos encontrarlo fácilmente con el operador de búsqueda site: de
los busdcadores:
site:infotics.es editor de textos
Resaltado de sintaxis en nano
Para activar el resaltado de sintaxis en nano enlazamos en el archivo de configuración de nano los archivos adecuados.
Primero comprobamos que están en /usr/share/nano. Si no está, podemos descargarnos unos archivos de
configuración que encontramos en este repositorio:
git clone https://github.com/scopatz/nanorc.git
Ahora que ya están, se puede editar el archivo de configuración de nano, .nanorc con nano ~/.nanorc:
include "~/.nanorc
Extra
Cron y crontab
Cron es un administrador de tareas programadas. Se activa cada minuto y examina las configuraciones que están en /etc/crontab y en las de cada usuarix.
¿Qué cosas se pueden hacer?
- Copia de seguridad automatizada.
- Registros de bases de datos.
- Sincronización de información.
Para listar las tareas
crontab -l
Para editar el archivo
Para editar el archivo propio de tareas, se hace con crontab -e:
crontab -e
Esto abrirá nuestro archivo de configuración de crontab con nuestro editor CLI que tengamos especificado en la
variable $EDITOR. Si no tenemos a nano, se puede usar el comando export para establecer la variable.
export EDITOR=nano
Eliminar el archivo
Para eliminar el archivo de crontab, tan solo hay que borrarlo con la opción -r:
crontab -r
Sintaxis
Se escriben cinco asteriscos separados por espacio o tabulación. En cada uno de los asteriscos se ponen valores para marcar el tiempo de ejecución del cron, en este orden:
- Minutos.
- Horas.
- Día en el mes.
- Mes.
- Día en la semana.
A continuación, va el comando a ejecutar.
- Asterisco: ejecución en todos los periodos de tiempo
El asterisco
*significa ejecutarse en todos los periodos de tiempo de esa unidad de tiempo, es decir:- Todos los minutos
- Todas las horas
- Todos los días del mes.
- Todos los meses
- Todos los días de la semana.
* * * * * comando a ejecutar - - - - - | | | | | | | | | +----- día en la semana (0 - 6) (domingo=0) | | | +------- mes (1 - 12) | | +--------- día en el mes (1 - 31) | +----------- hora (0 - 23) +------------- minuto (0 - 59)
- Periodos concretos
Se pueden elegir periodos de tiempo, por ejemplo,
*/15 * * * * /home/flow/scripts/fecha.sh
Ejecutará el script cada 15 minutos por el valor
*/15en minutos y*en los demás.O bien cada cinco horas:
0 */5 * * * /home/flow/scripts/fecha.sh
- Rangos
Se puede elegir un rango:
* 6-8 * * * /home/flow/scripts/fecha.sh
- De las 6 a las 8 AM por el valor
6-8, en cada minuto por el valor*de minuto.
O varios, separados por comas:
0 8-12,14-20 * * * /home/flow/scripts/fecha.sh
- Rangos: de 8 a 12 y de 14 a 20 horas.
- Cada hora exacta: minuto 0, el primer valor.
- De las 6 a las 8 AM por el valor
- Un día concreto a una hora
0 6 1 * * /home/flow/scripts/fecha.sh
- Todos los días a una hora concreta
0 6,20 * * * /home/flow/scripts/fecha.sh
- Se ejecuta todos los días por el valor 0.
- A las 6,20 por el valor 6,20 en las horas.
- Todos los días de un mes a una hora exacta
0 6 * 1 * /home/flow/scripts/fecha.sh
- Todos los días de enero por el valor 1 en mes y * en días.
- A las 6 AM por el valor 6 de hora y 0 de minuto.
- Todos los lunes a las 6 horas
0 6 * * 1 /home/flow/scripts/fecha.sh
- Todos los lunes por el valor 1 (el primer día es el domingo que es valor 0).
- A las 6 AM por el valor 6 de hora y 0 de minuto.
Una tarea del cron
Vamos a crear un script para crear una tarea:
nano scripts/fecha.sh
Y el contenido es:
#/bin/bash date >> /tmp/fecha.log
Cambiamos los permisos de este archivo para hacerlo ejecutable:
chmod u-x scripts/fecha.sh
Lo ejecutamos para comprobar que funciona:
.scripts/fecha.sh
Y a su vez comprobamos que ha resultado con cat:
cat /tmp/fecha.log
Si en vez de cada minuto queremos hacerlo cada 10 minutos, hemos de fraccionarlo por 10:
*/10 * * * * /home/flow/scripts/fecha.sh
Algunos enlaces desordenados
- https://www.thegeekstuff.com/2013/06/cut-command-examples/
- https://github.com/rosepac/biblioteca-espanol-gratis/blob/master/libros-programacion-gratis.md#emacs
- https://es.wikibooks.org/wiki/El_Manual_de_BASH_Scripting_Básico_para_Principiantes
- https://twitter.com/climagic/
- https://github.com/rastapasta/mapscii
- mapscii: telnet mapscii.me
- fancy-prompt-macosx: https://github.com/ThatJoeMoore/fancy-prompt
- https://github.com/andresgongora/scripts/blob/master/fancy-bash-promt.sh
- https://stackoverflow.com/questions/10172327/linux-curl-save-as-utf-8
- https://www.class-central.com/
- https://www.nanotutoriales.com/introduccion-a-cron
- https://www.gnu.org/software/bash/manual/bashref.html
- https://www.linux.com/learn/how-make-fancy-and-useful-bash-prompt-linux
- https://ss64.com/